60年技术简史,带你读懂AI的前世今生
|
天然说话处理赏罚的使命太多了,除了呆板翻译等少数直接面向应用而且有很强现实需求的使命有较量多的数据外,大部门使命的标注数据很是有限。和ImageNet这种上百万的标注数据集可能语音辨认几千小时的标注数据集对比,许多天然说话处理赏罚的标注数据都是在几万最多在几十万这样的数目级。这是由天然说话处理赏罚的特点抉择的,由于它是跟详细营业相干的。因此天然说话处理赏罚规模一向急需办理的就是怎么从未标注的数据里进修出有效的常识,这些常识包罗语法的、语义的和天下常识。 Mikolov等人2013年在《Efficient estimation of word representations in vector space》和《Distributed representations of words and phrases and their compositionality》开始了这段征程。他们提出的Word2Vec可以简朴高效的进修出很好的词向量,如下图所示。
图:Word2Vec的词向量 从上图我们可以发明它确实学到了一些语义常识,通过向量计较可以获得相同”man-woman=king-queen”。 我们可以把这些词向量作为其余使命的初始值。假如下流使命数据量很少,我们乃至可以牢靠住这些预实习的词向量,然后只调解更上层的参数。Pennington等人在2014年的论文《Glove: Global vectors for word representation》里提出了GloVe模子。 可是Word2Vec无法思量上下文的信息,好比”bank”有银行和水边的意思。可是它无法判定详细在某个句子里到底是哪个意思,因此它只能把这两个语义同时编码进这个向量里。可是在下流应用中的详细某个句子里,只有一个语义是必要的。虽然也有实行办理多义词的题目,好比Neelakantan等人在2014年的《Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space》,但都不是很乐成。 其它一种办理上下文的器材就是RNN。可是平凡的RNN有梯度消散的题目,因此更常用的是LSTM。LSTM早在1997年就被Sepp Hochreiter和Jürgen Schmidhuber提出了。在2016年前后才大量被用于天然说话处理赏罚使命,成为其时文本处理赏罚的”究竟”尺度——各人以为任何一个使命起首应该就行使LSTM。虽然LSTM的其余变体以及新提出的GRU也获得普及的应用。RNN除了可以或许进修上下文的语义相关,理论上还能办理长间隔的语义依靠相关(虽然纵然引入了门的机制,现实上太长的语义干厦魅照旧很难进修)。
图:LSTM 许多NLP的输入是一个序列,输出也是一个序列,并且它们之间并没有严酷的次序和对应相关。为了办理这个题目,seq2seq模子被提了出来。最终行使seq2seq的是呆板翻译。Sutskever等人在2014年的论文《Sequence to Sequence Learning with Neural Networks》初次行使了seq2seq模子来做呆板翻译,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》里初次把Attention机制引入了呆板翻译,从而可以进步长句子的翻译结果。而Google在论文里《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》先容了他们现实体系中行使神经收集呆板翻译的一些履历,这是初次在业界应用的神经收集翻译体系。
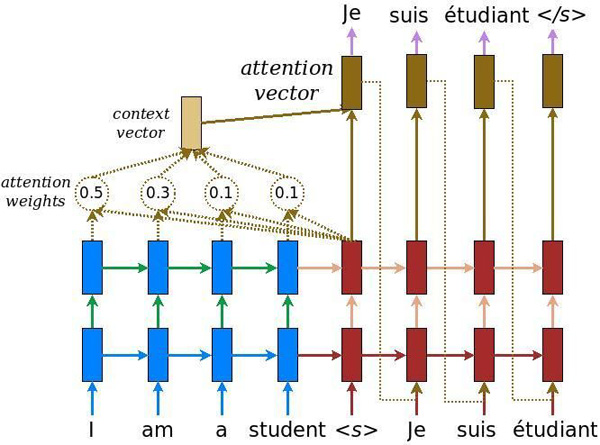
图:LSTM seq2seq加Attention成为了办理许多题目的尺度要领,包罗择要、问答乃至对话体系开始风行这种End-to-End的seq2seq模子。 Google2017年在《Attention is All You Need》更是把Attention机制推向了极致,它提出了Transformer模子。由于Attention相对付RNN来说可以更好的并行,并且它的Self-Attention机制可以同时编码上下文的信息,它在呆板翻译的WMT14数据上取得了第一的后果。
图:Neural Machine Translation (编辑:湖南网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |