60年技术简史,带你读懂AI的前世今生
|
这篇论文的设法着实很是很是简朴,但取得了很是好的结果。它的思绪是用深度的双向RNN(LSTM)在大量未标注数据上实习说话模子,如下图所示。然后在现实的使命中,对付输入的句子,我们行使这个说话模子来对它处理赏罚,获得输出的向量,因此这可以当作是一种特性提取。可是和平凡的Word2Vec可能GloVe的pretraining差异,ELMo获得的Embedding是有上下文的。 好比我们行使Word2Vec也可以获得词”bank”的Embedding,我们可以以为这个Embedding包括了bank的语义。可是bank有许多意思,可所以银行也可所以水边,行使平凡的Word2Vec作为Pretraining的Embedding,只能同时把这两种语义都编码进向量里,然后靠后头的模子好比RNN来按照上下文选择吻合的语义——好比上下文有money,那么它更也许是银行;而假如上下文是river,那么更也许是水边的意思。可是RNN要学到这种上下文的相关,必要这个使命有大量相干的标注数据,这在许多时辰是没有的。而ELMo的特性提取可以当作是上下文相干的,假如输入句子有money,那么它就(可能我们祈望)应该能知道bank更也许的语义,从而帮我们选择越发吻合的编码。
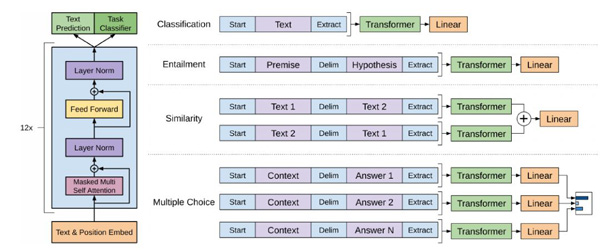
图:RNN说话模子 ELMo学到的说话模子参数是牢靠的,下流的使命把它的隐状态作为特性。而来自论文《Improving Language Understanding by Generative Pre-Training》的OpenAI GPT模子会按照特定的使命举办调解(凡是是微调),这样获得的句子暗示能更好的适配特定使命。它的头脑着实也很简朴,行使Transformer来进修一个说话模子,对句子举办无监视的Embedding,然后按照详细使命对Transformer的参数举办微调。由于实习的使命说话模子的输入是一个句子,可是下流的许多使命的输入是两个,因此OpenAI GPT通过在两个句子之前插手非凡的脱离符来处理赏罚两个输入,如下图所示。
图:OpenAI GPT处理赏罚下流使命的要领 OpenAI GPT取得了很是好的结果,在许多使命上远超之前的第一。 ELMo和GPT最大的题目就是传统的说话模子是单向的——我们是按照之前的汗青来猜测当前词。可是我们不能操作后头的信息。好比句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时辰必要同时操作前后的信息,由于在这个句子中,it也许指代animal也也许指代street。按照tired,我们揣度它指代的是animal,由于street是不能tired。可是假如把tired改成wide,那么it就是指代street了。 传统的说话模子,不管是RNN照旧Transformer,它都只能操作单偏向的信息。好比前向的RNN,在编码it的时辰它看到了animal和street,可是它还没有看到tired,因此它不能确定it到底指代什么。假如是后向的RNN,在编码的时辰它看到了tired,可是它还基础没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,可是按照前面的先容,因为我们必要用Transformer来进修说话模子,必需用Mask来让它看不到将来的信息,因此它也不能办理这个题目。 那它是怎么办理说话模子只能操作一个偏向的信息的题目?谜底是它的pretraining实习的不是平凡的说话模子,而是Mask说话模子。这个思绪是在Google的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》里提出了,也就是我们此刻熟知的BERT模子。 BERT一出来就横扫了各类NLP的评测榜单,引起了极大的存眷。就在媒体都在用”最强NLP模子”之类的词歌咏BERT的时辰,最近又呈现了XLNet,又一次横扫了各大榜单。它以为BERT有两大题目:它假设被Mask的词之间在给定其余非Mask词的前提下是独立的,这个前提并不创立;Pretraining的时辰引入了非凡的[MASK],可是fine-tuing又没有,这会造成不匹配。XLNet通过Permutation说话模子来办理平凡说话模子单向信息流的题目,同时小心Transformer-XL的利益。通过Two-Stream Self-Attention办理target unaware的题目,最终实习的模子在许多使命上高出BERT缔造了新的记录。 强化进修 强化进修和视觉、听觉和说话着实不是一个层面上的对象,它更多的是和监视进修、非监视进修并行的一类进修机制(算法),可是我以为强化进修长短常重要的一种进修机制。 (编辑:湖南网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |